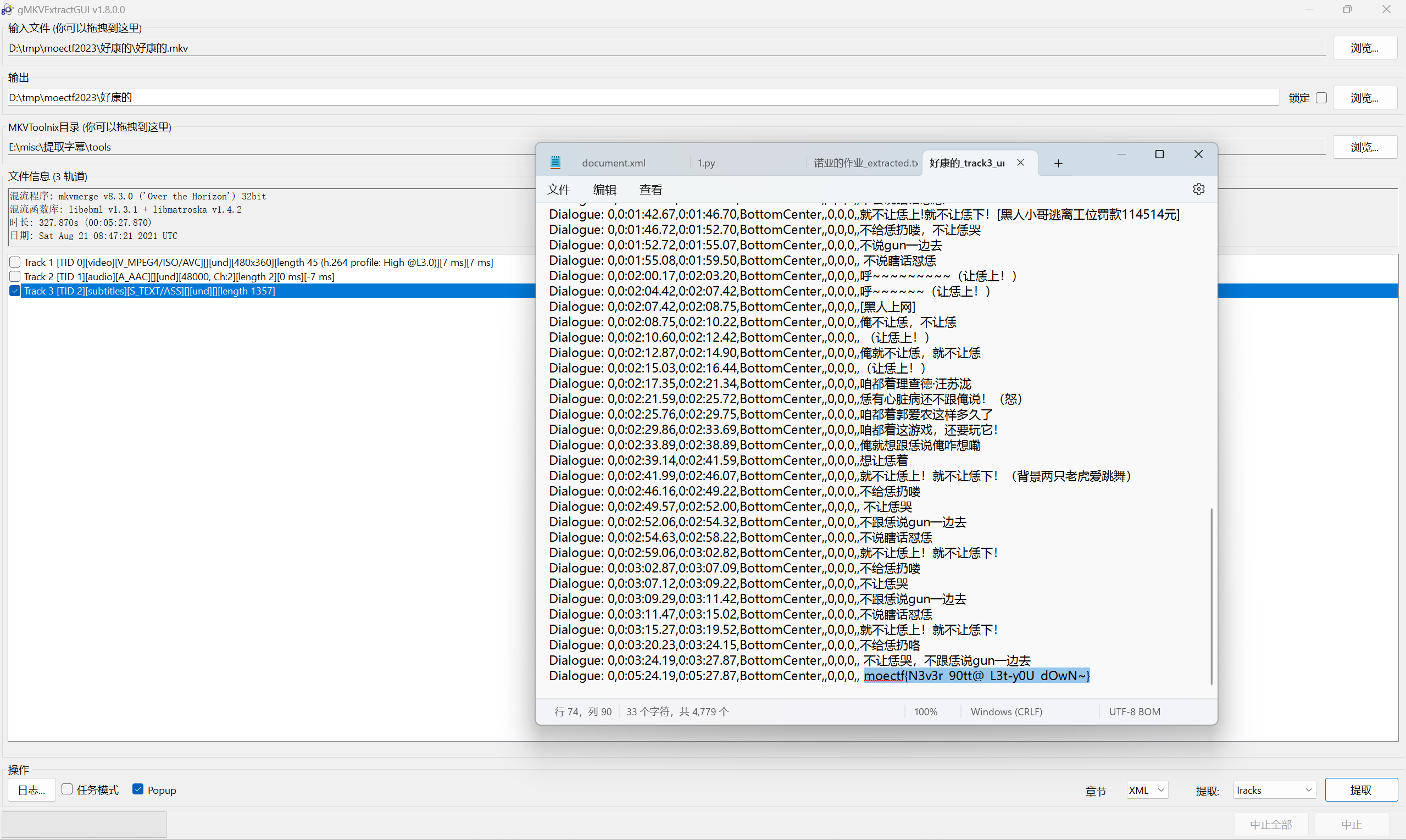
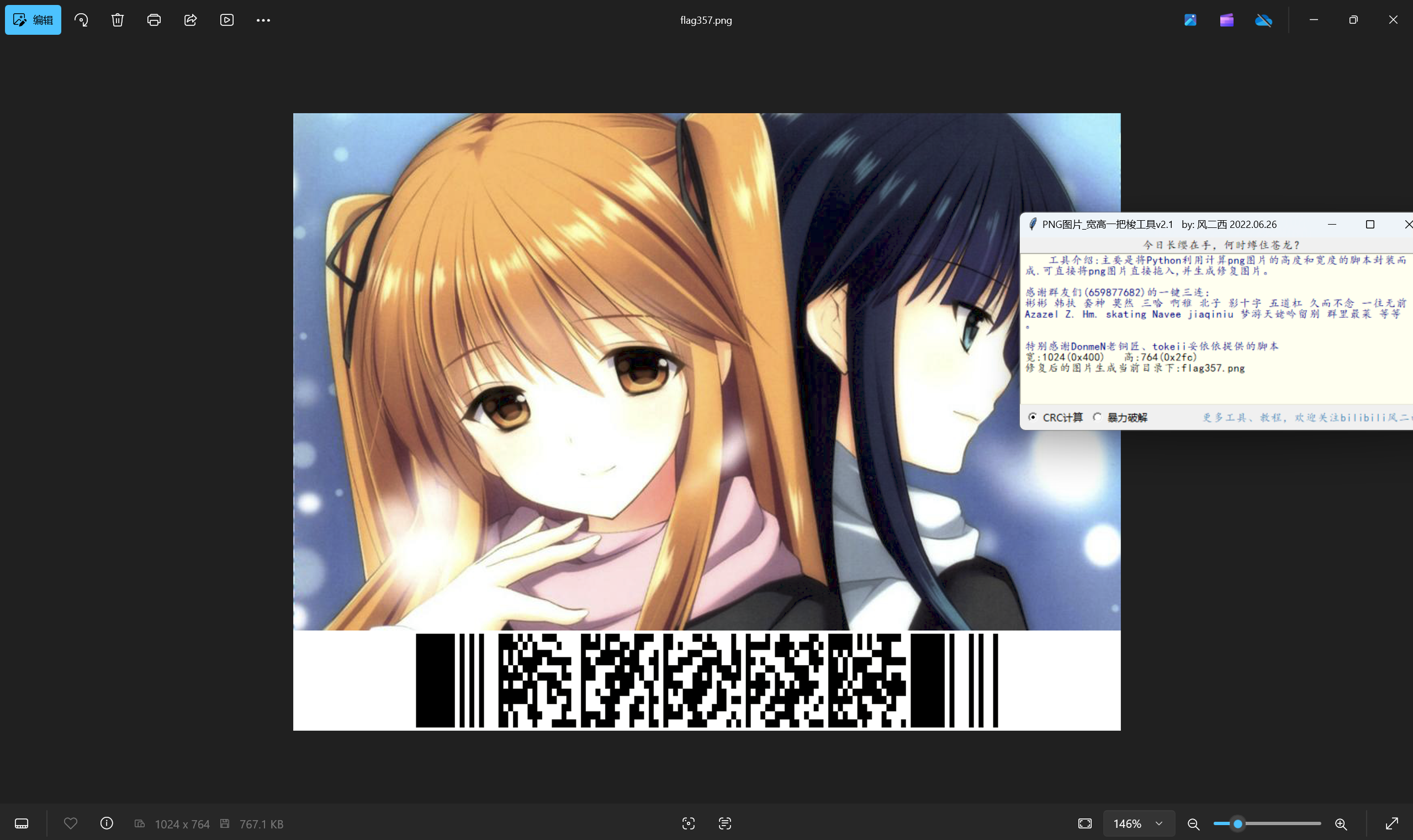
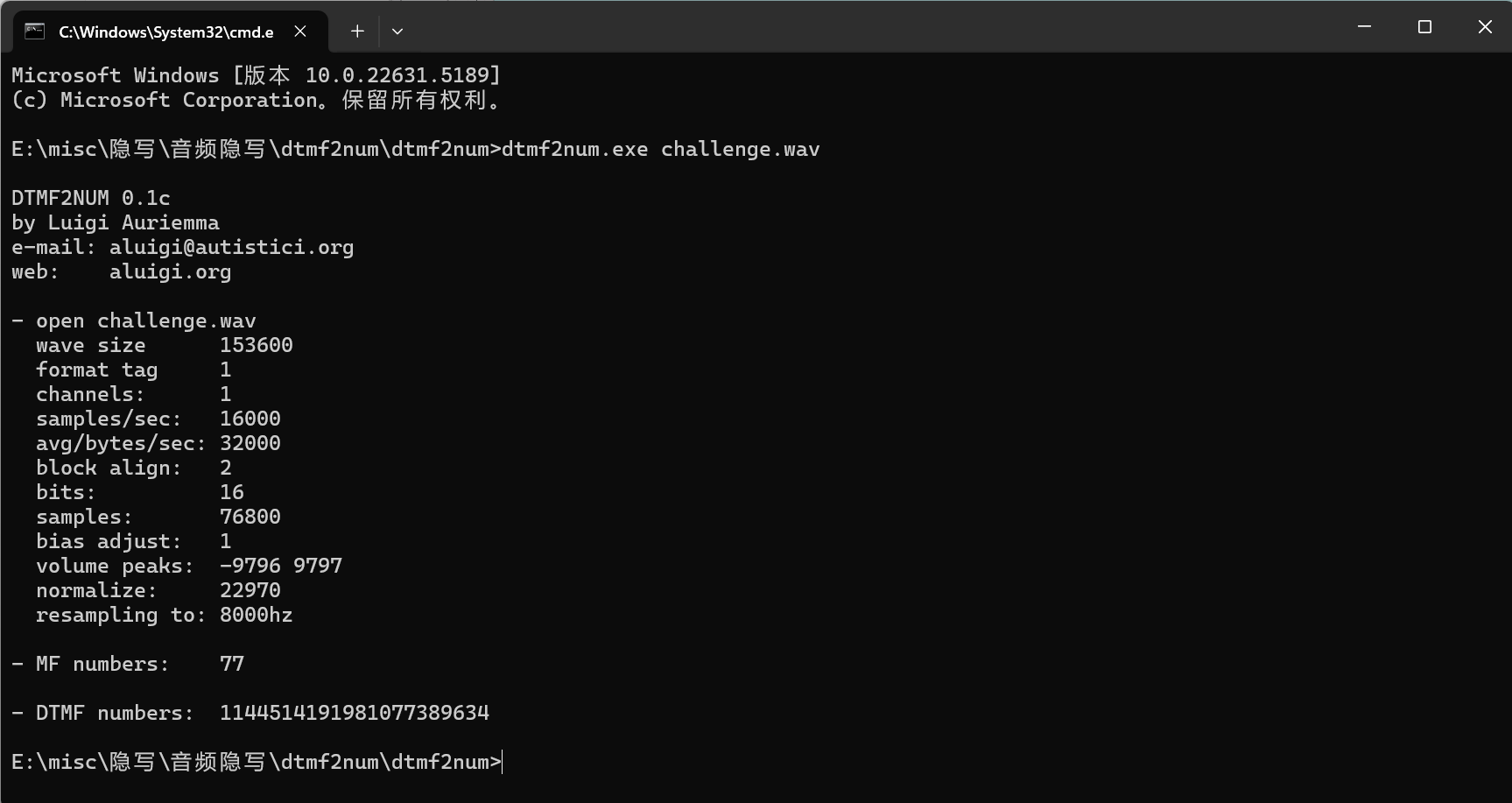
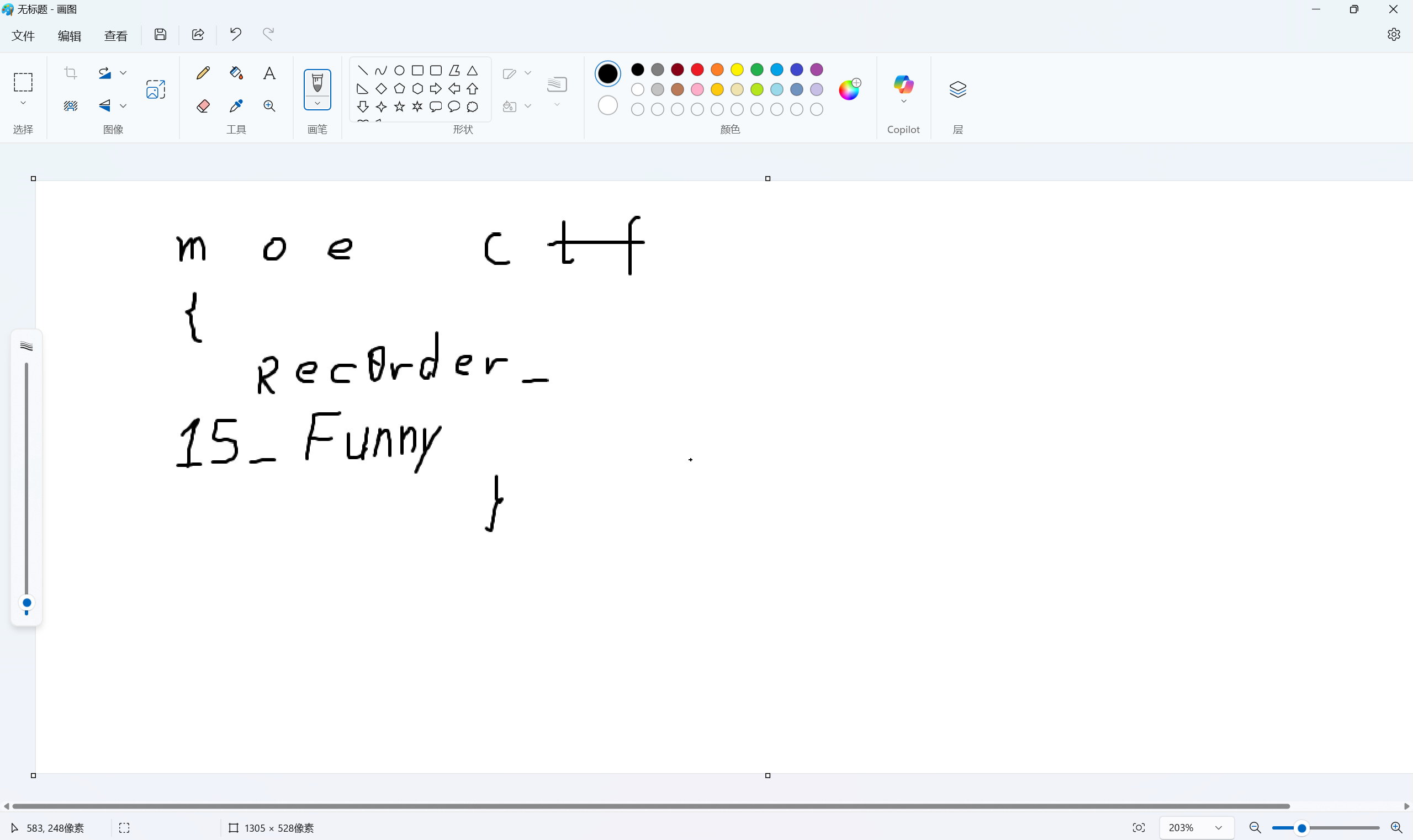
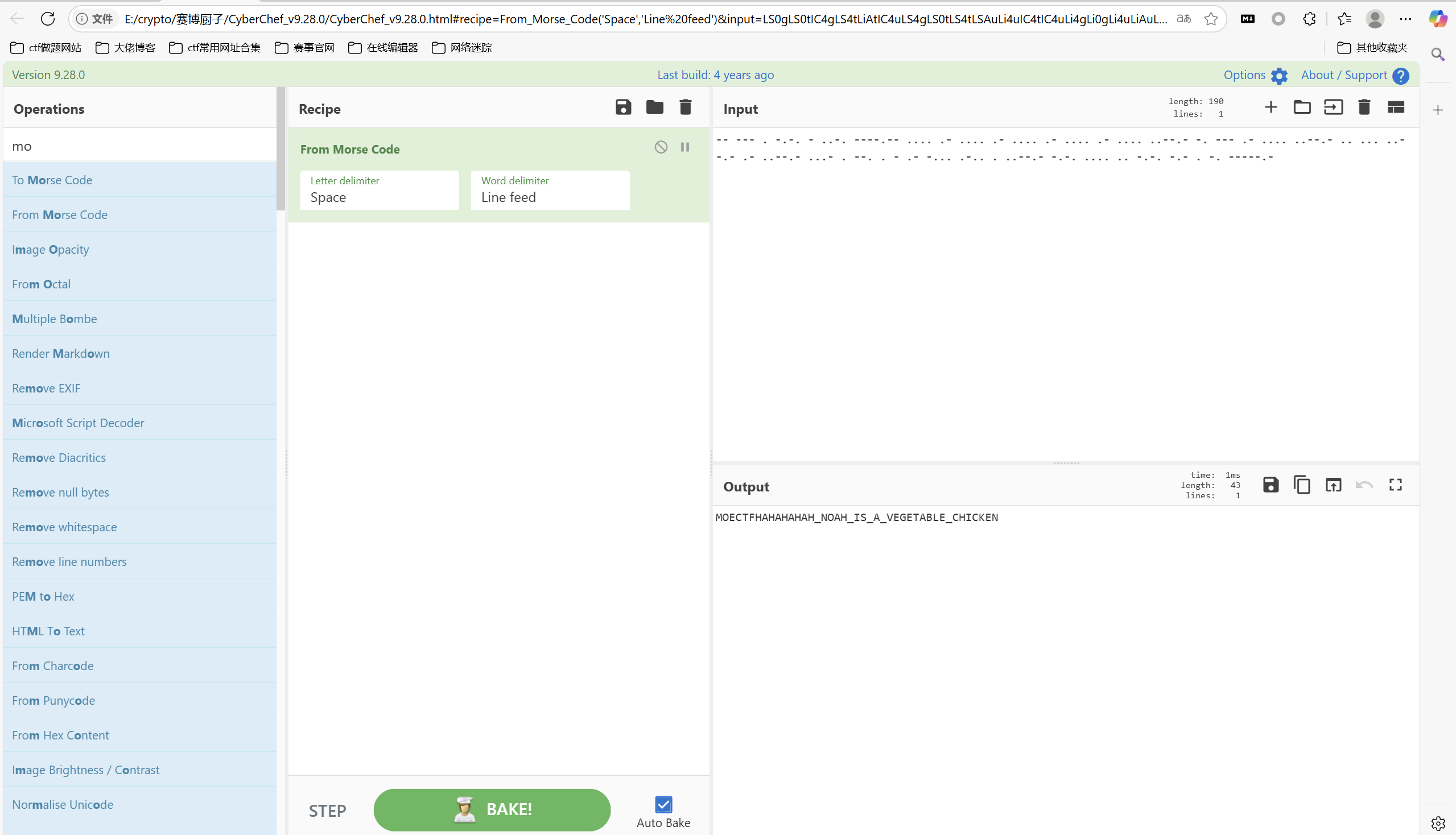
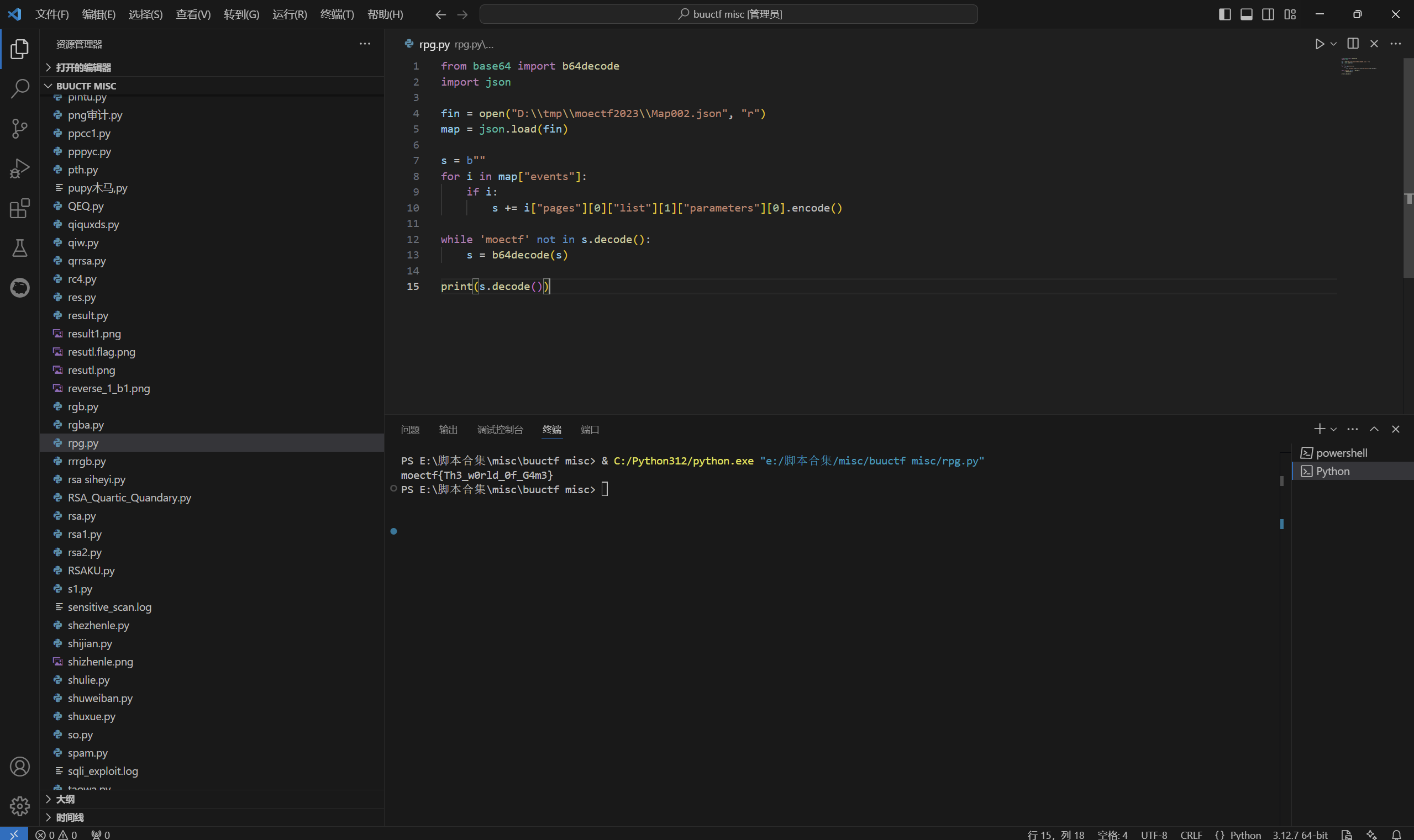
import re import sys import zipfile from bs4 import BeautifulSoup
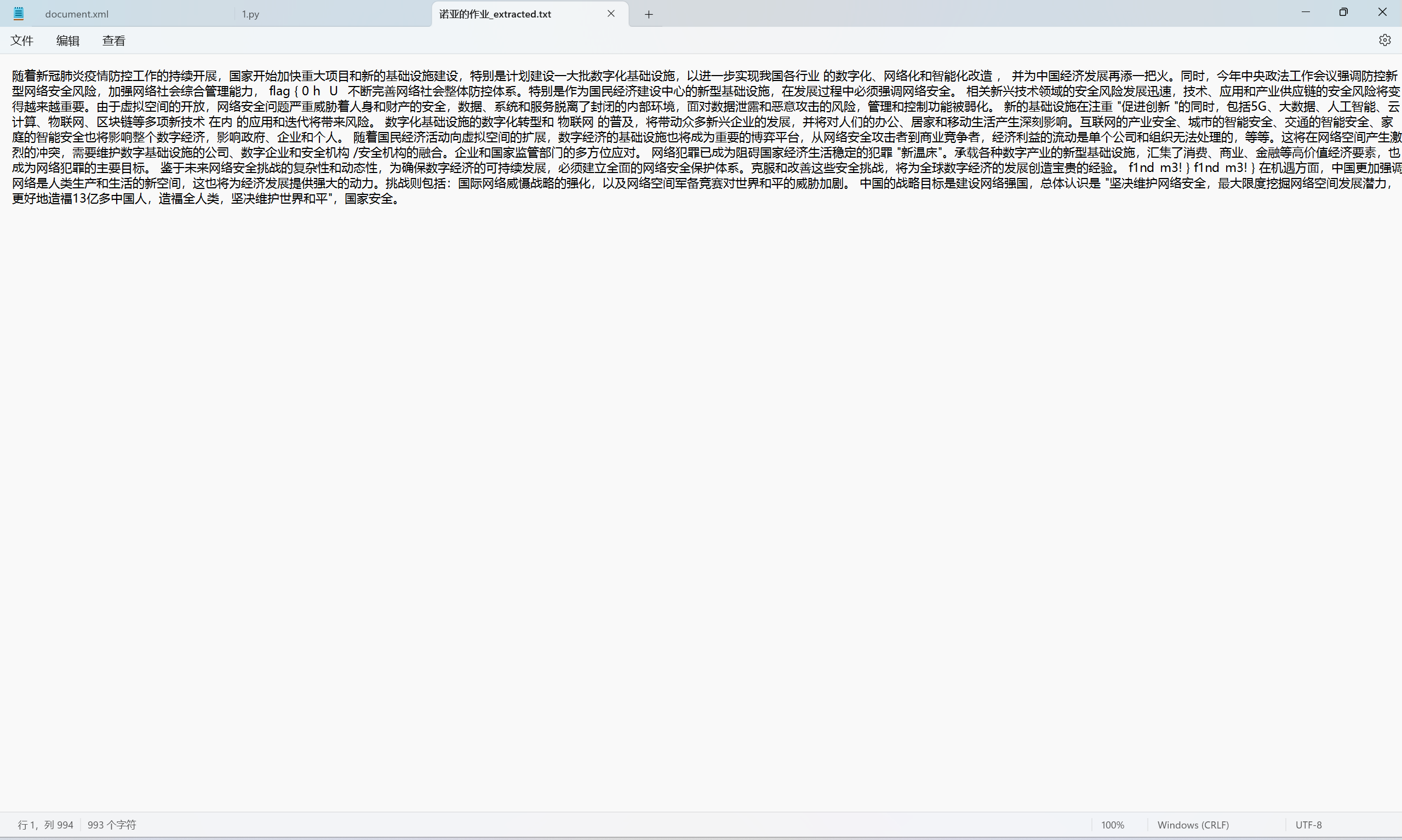
def extract_text_from_docx(docx_path): """从 DOCX 文件中提取纯文本""" try: with zipfile.ZipFile(docx_path) as docx: # Word 文档的主要文本存储在 word/document.xml with docx.open('word/document.xml') as xml_file: xml_content = xml_file.read().decode('utf-8') # 解析 XML 并提取文本 soup = BeautifulSoup(xml_content, 'lxml-xml') text_elements = soup.find_all('w:t') # Word 文本标签 text = ' '.join([elem.get_text() for elem in text_elements]) # 清理文本 text = re.sub(r'\s+', ' ', text).strip() return text except Exception as e: print(f"处理文件时出错: {e}") return None
def main(): if len(sys.argv) != 2: print("用法: python docx_text_extractor.py <input.docx>") sys.exit(1) input_file = sys.argv[1] if not input_file.lower().endswith('.docx'): print("错误: 请提供一个 DOCX 格式的文件") sys.exit(1) text = extract_text_from_docx(input_file) if text: output_file = input_file.replace('.docx', '_extracted.txt') with open(output_file, 'w', encoding='utf-8') as f: f.write(text) print(f"文本已成功提取并保存到 {output_file}") else: sys.exit(1)
for root, dirs, files in os.walk("D:\\tmp\\moectf2023\\file\\"): for directory in dirs: # 避免使用内置函数名dir作为变量名 try: # 假设目录名格式为"xxx yyy",取第二部分 part = directory.split()[1] data += part except (IndexError, ValueError): # 处理目录名不符合预期格式的情况 print(f"Skipping directory: {directory} (invalid format)")
# 修正变量名,将file改为data data = data.replace("_", "/")
try: with open("D:\\tmp\\moectf2023\\file.out", "wb") as fout: fout.write(bd(data)) print("Base64 decoded and written to file successfully.") except Exception as e: print(f"Error: {e}") print(f"Data content: {data[:50]}...") # 打印前50个字符用于调试